Nueva web del Real Madrid - Impacto en SEO y CWV
Tiempo de lectura: 13 minsEl Real Madrid cambió su web recientemente. Y te preguntarás que por qué hago un artículo sobre este tema siendo yo una fiel seguidora del RCD Espanyol. No te preocupes, todo tiene una explicación.
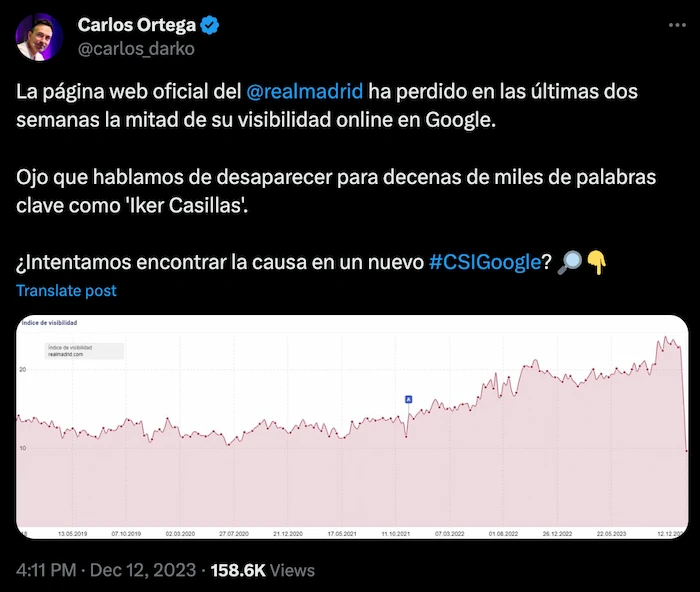
Recientemente, Carlos Ortega hizo un hilo en Twitter analizando la caída de visibilidad que había detectado en la web del Real Madrid. Si no lo has visto, lo tienes aquí:
Pero, más allá del impacto a nivel SEO, a mí me preocupaba ver si también había sufrido una caída a nivel Core Web Vitals. Deformación profesional, lo sé.
Vayamos pues paso por paso desgranando lo que ha ocurrido y cómo ha podido impactar a nivel SEO y Core Web Vitals.
Migraciones y dolores de cabeza #
Cada vez que veo una gráfica de Sistrix con una caída del índice de visibilidad, lo primero que me viene a la cabeza es "¿han hecho una migración?". Porque, en mi experiencia, un cambio tan brusco suele ser por esa razón.
Y así ha sido en este caso. Carlos explica cómo llegó a esa misma conclusión en su hilo en twitter, pero también puedes ir directamente a Wayback Machine y comparar la home antes y después.
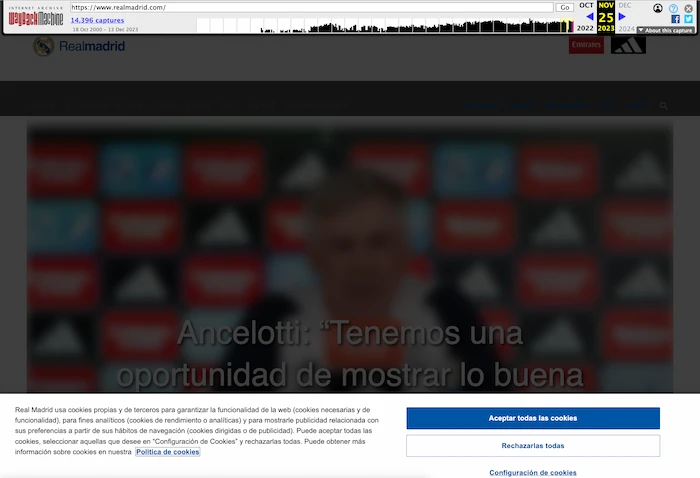
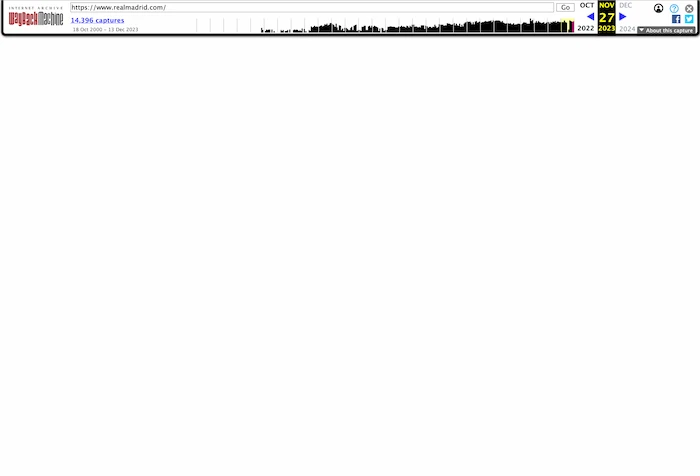
Los pantallazos actuales muestran una pantalla en blanco, pero más adelante veremos que hay más de lo que tus ojos ven (guiño guiño).
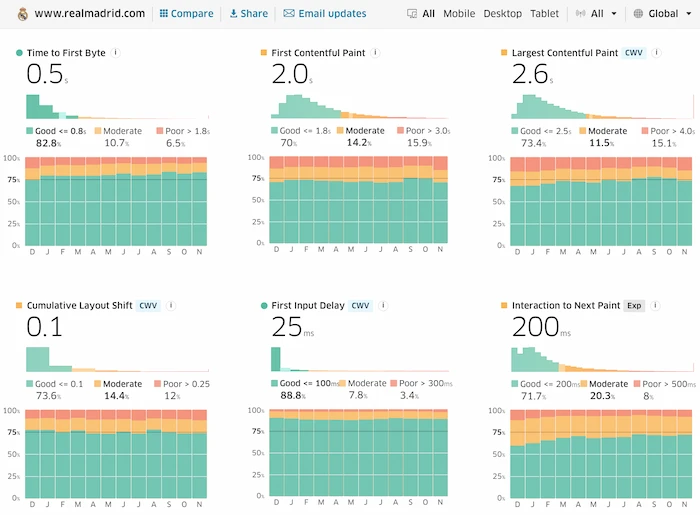
Navegando entre los screenshots disponibles, vemos que el cambio sucedió entre el 25 y el 27 de noviembre. Al ser este cambio a final de mes, vemos en los datos del CrUX correspondientes al mes de noviembre que hay una ligera caída en FCP y LCP pero no parece nada crítico (todavía):
Stack tecnológico y sistema de renderizado #
Sin entrar demasiado en materia, no sé con qué tecnología(s) estaba hecha la web viendo la información disponible en Wayback Machine. Pero desde el servidor se servía el contenido y los estilos necesarios para renderizar el contenido principal.
Pero si analizamos la web actual, vemos que es completamente distinta. Como hemos visto antes, en Wayback Machine vemos una pantalla completamente en blanco y vemos peticiones que nos hacen sospechar que al menos utilizan Adobe AEM y Angular.
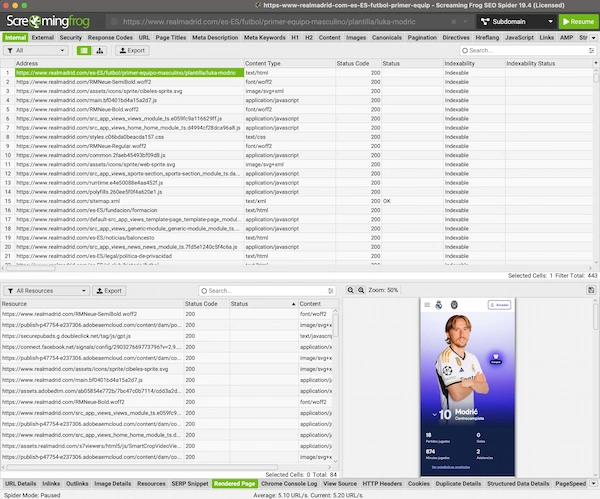
¿Pero es realmente una web CSR con contenido generado en cliente? El hecho de que sin JS la web actual no muestra contenido nos haría sospechar que sí. De aquí en adelante me centraré en la ficha de Luka Modric, como ha hecho Carlos en su hilo.
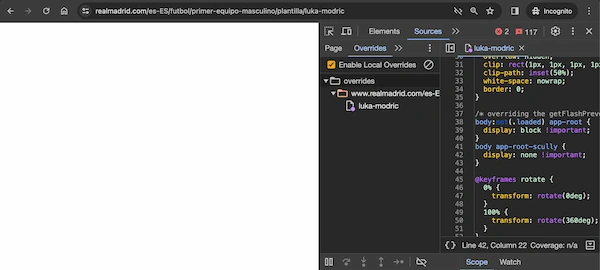
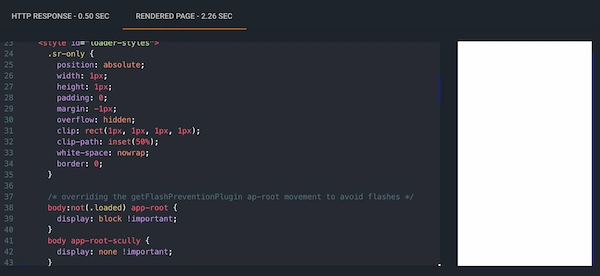
Pero si echamos un ojo al HTML que sirve el servidor vemos que no es del todo cierto que sea CSR. Vemos que se están utilizando Custom Elements pero no estamos hablando de contenido generado por JS en el shadow DOM en cliente. La estrategia es distinta. El contenido ESTÁ en la página desde el inicio, pero no se muestra porque hay una directiva CSS de display: none !important; que aplica al Custom Element <app-root-scully> que sirve de wrapper del contenido.
body app-root-scully {
display: none !important;
}Lo podemos ver cargando la página sin JavaScript pero haciendo override de la directiva display: none !important; que aplica al elemento <app-root-scully> por display: block !important;:
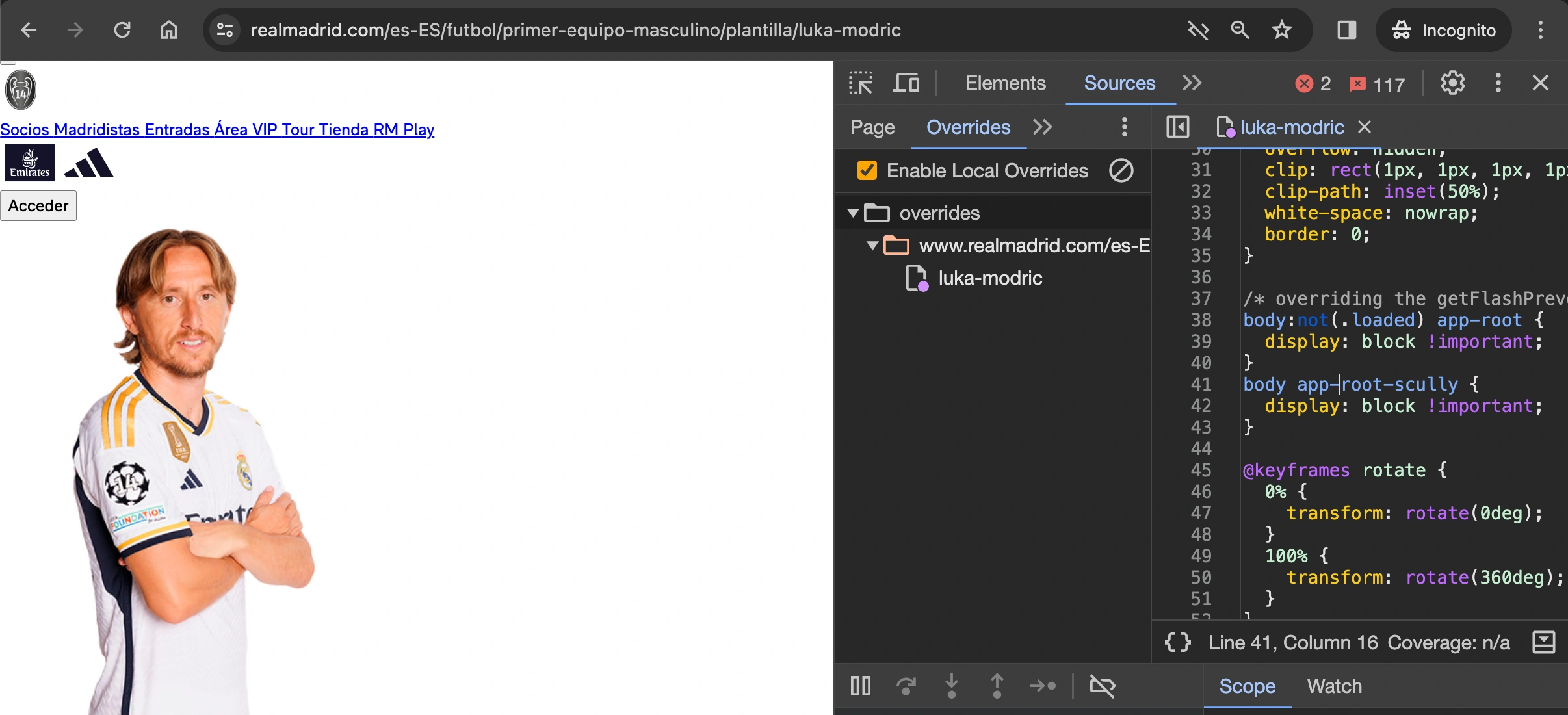
¿Cuál es entonces la estrategia que se está utilizando? Vayamos paso a paso.
El servidor envía un documento HTML en el que está el contenido que finalmente se mostrará en pantalla. Pero, de inicio, está oculto. A su vez, hay código JavaScript que elimina el wrapper que tiene la directiva display: none !important;:
Esto lo podemos comprobar comparando las diferencias entre el raw HTML y el rendered HTML:
- <app-root rm-version="2.0.0-SNAPSHOT" rm-lib-version="6.3.129"></app-root>
- <app-root-scully rm-version="2.0.0-SNAPSHOT" rm-lib-version="6.3.129" _nghost-bfx-c63="" ng-version="14.2.8">
- <router-outlet _ngcontent-bfx-c63=""></router-outlet>
+<app-root rm-version="2.0.10" rm-lib-version="6.3.134" _nghost-fep-c63="" ng-version="14.2.8">
+ <router-outlet _ngcontent-fep-c63=""></router-outlet>Como hemos visto, el contenido está, pero oculto. No obstante, al hacerlo "visible", vemos el contenido pero los estilos distan mucho de ser los que vemos con JS activado. Y es que, además de eliminar el tag <app-root-scully>, y entre otras cosas, se están inyectando con JS varias etiquetas <style> con el CSS necesario para que finalmente se vea todo bien.
¿Y Google qué opina de esto? #
Esto en sí mismo no debería ser un problema dramático a nivel rastreo/indexación, puesto que hemos visto que el contenido está en el HTML y es finalmente renderizado con los estilos pertinentes via JS.
Sin embargo, en su hilo en Twitter, Carlos comentaba que Googlebot no era capaz de ver el contenido. Profundicemos un poco más en este tema.
Primero de todo, en caso de que estemos analizando una página que tenga contenido generado con JavaScript, hemos de tener en cuenta que cargar la página sin JS no es sinónimo de cargar la página como la ve Google. En todo caso es sinónimo de cómo ve la página durante la primera ola de indexación - pero en la segunda, descargará y ejecutará el JS necesario para renderizar y leer el contenido generado por ese JS.
Por otro lado, comprobar la caché de Google para páginas CSR probablemente no nos servirá de nada. ¿Por qué? Google guarda una versión del HTML que recibe del servidor (no una versión del HTML renderizado). Esto significa que la página se carga desde un dominio de Google, pero se harán peticiones al servidor de origen para descargar el resto de archivos necesarios para su carga. Y, en el caso de JavaScript, existen limitaciones.
John Mueller lo explica mucho mejor de lo que yo lo pueda hacer en este vídeo:
Dicho esto, recordemos que el caso que nos ocupa hoy no es exactamente una página que tenga contenido generado por JavaScript. Como hemos visto antes, el contenido está allí - pero no se muestra por la directiva display: none !important; que se aplica sobre el Custom Element <app-root-scully>. ¿Pero es Google capaz de renderizarlo con los estilos pertinentes?
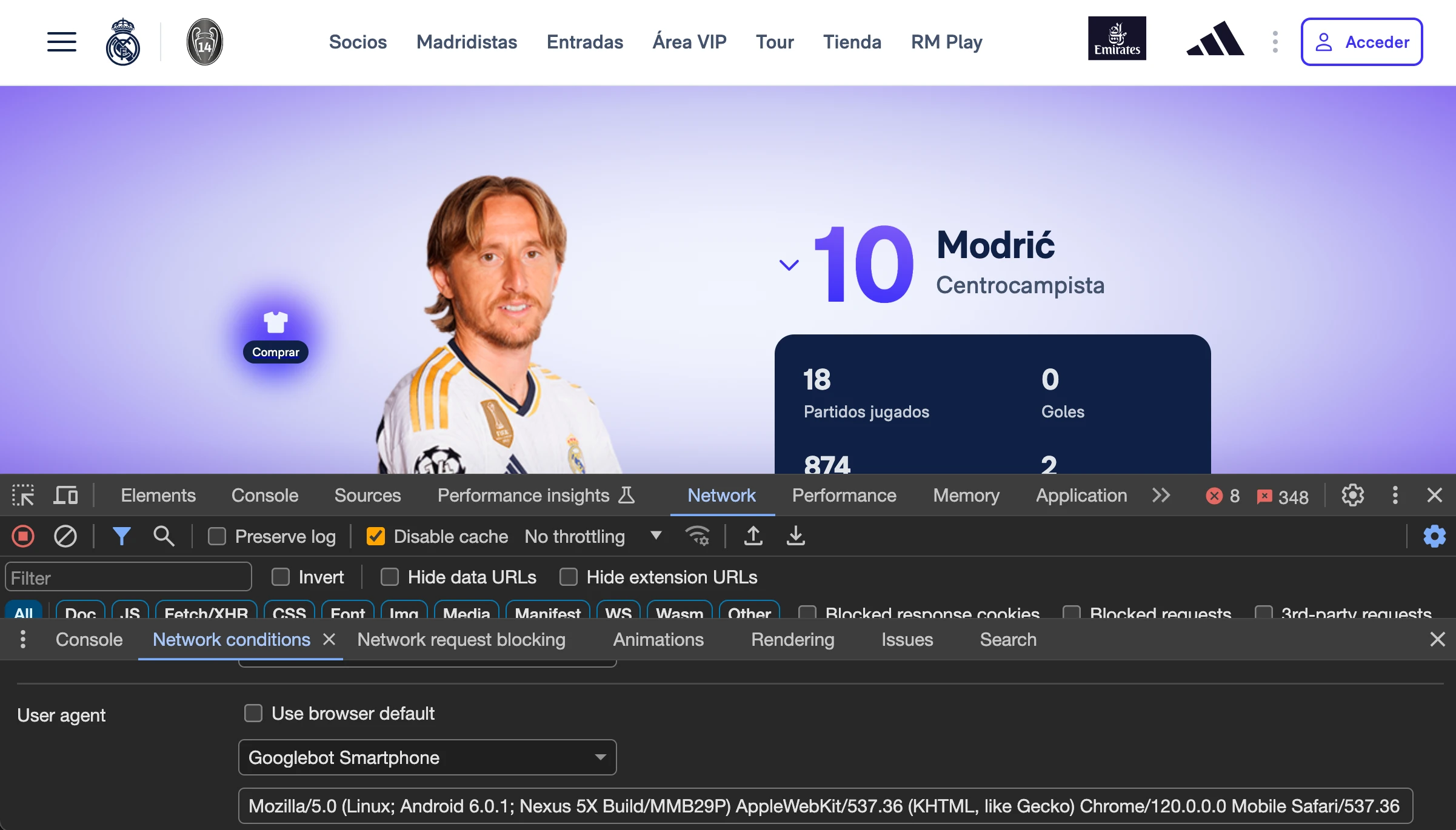
Usando la herramienta Fetch and Render de Merkle parece que no:
Pero echando un ojo al código de la versión renderizada que devuelve esta herramienta vemos que en realidad es el raw HTML. No sé exactamente por qué, ya que con otras herramientas sí se ve el contenido correctamente renderizado.
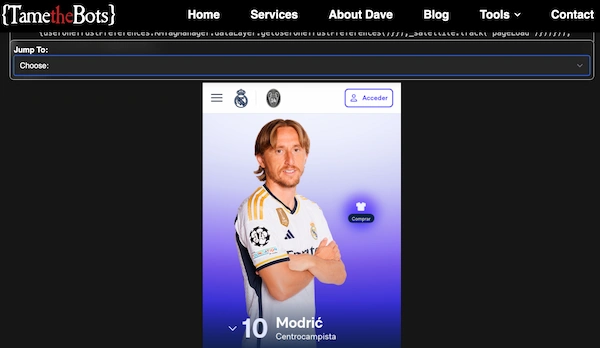
Así que, y sin poder comprobarlo en Search Console que sería la fuente de la verdad, me decanto por pensar que Google es capaz de renderizar bien la página.
Sin embargo, veíamos al inicio de este artículo que la visibilidad ha caído en picado. ¿Por qué?
En este sentido, Carlos ya había detectado que el mapeo de redirecciones no era el óptimo. Y también sabemos que esto es un fallo que puede resultar crítico en una migración. Pero, además, vemos que ahora todas las páginas de la web tienen el mismo title cuando antes no era así.
El HTML que se sirve desde servidor tiene un title por defecto que luego se actualiza con un patrón por JS. Pero que finalmente resulta ser el mismo contenido que el que había en el HTML inicial:
- <title>Real Madrid CF | Web Oficial del Real Madrid CF</title>
+ <title>web.meta:title:home</title>Y esa meta información está disponible en el archivo https://publish-p47754-e237306.adobeaemcloud.com/content/dam/common/statics/public-content/internet/web/rm-spa-web/i18n/es-ES.json. ¿Y cuál es el contenido de web.meta:title:home en ese archivo JSON? Efectivamente, el mismo que teníamos en el title por defecto:
"web.meta:title:home": "Real Madrid CF | Web Oficial del Real Madrid CF",Es decir, en el HTML se informa de un title. Y, dinámicamente, se cambia por un tag title que contiene el mismo contenido que el que teníamos en el raw HTM - y que es el mismo para todas las páginas de la nueva web.
Esto puede que sea un error (que se esté referenciando erróneamente a web.meta:title:home en vez de a web.meta:title:[pagina-actual]) o que en una primera iteración se ha salido con el contenido de la home para todas las páginas mientras se trabaja en una próxima iteración en la que estará la información correcta para cada página.
En cualquier caso, Google hace lo que puede con lo que le damos. Y, en este caso, coge el H1 "Modric" y lo utiliza como "title" en las SERP porque entiende que ese elemento es más acertado como title que no el de la home.
Así pues, mi hipótesis sobre la caída en el índice de visibilidad va más encaminada a los siguientes puntos:
- Un mapeo de redirecciones que no es el óptimo
- Google necesita de algo más de tiempo para entender cuál es el contenido principal de cada página al no tener unos titles únicos y específicos para cada página.
Impacto: ¿solo en SEO? #
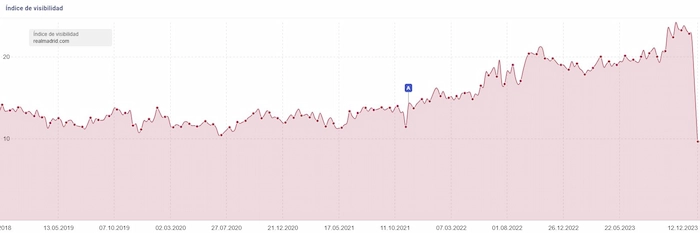
Debido a todo esto, vemos lo que Carlos compartía en el tuit inicial de su hilo sobre este caso: una caída significativa en el índice de visibilidad en la herramienta Sistrix.
Pero hay más daños colaterales. Como hemos visto, se está ocultando el contenido con una directiva display: none !important; hasta que JS hace su magia y elimina el tag que sigue esa directiva, mientras inyecta nuevos estilos y estos son aplicados. Y ya sabemos que todo lo que sea depender de que JS modifique el DOM significa tiempo.
Sí, efectivamente, afecta a las Core Web Vitals y otras Web Vitals relacionadas.
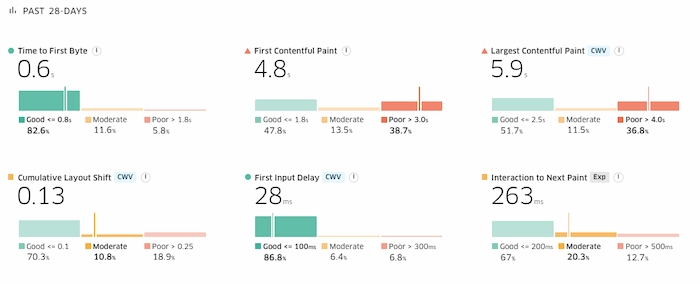
Por un lado, afecta de forma directa a las métricas de carga First Contentful Paint (FCP) y Largest Contentful Paint (LCP), ya que el contenido no es visible hasta que JS aplica los cambios ya mencionados.
Lo podemos ver en los resultados agregados de CrUX para los últimos 28 días y comparándolo con los resultados de los meses anteriores:
Pero vemos que también impacta sobre el Cumulative Layout Shift (CLS).
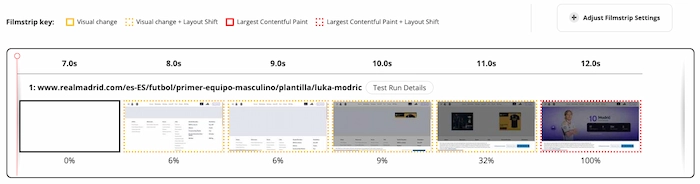
Al inyectar los estilos también via JS, además de eliminar elementos y cambiar atributos y clases, hacemos que el navegador tenga que recalcular los estilos de los elementos y aplicarlos según se vayan resolviendo. Es por esto por lo que vemos que, durante la carga, lo primero que se renderiza es el footer para posteriormente ir cargando los elementos superiores que a su vez van "empujando" el footer hacia abajo (y generando CLS).
En resumen, mirando el P75, observamos la siguiente degradación
- FCP: pasa de 2.0 s a 4.8 s
- LCP: pasa de 2.6 s a 5.9 s
- CLS: pasa de 0.1 a 0.13
Conclusiones #
Una migración es siempre un proceso crítico que puede afectar de forma muy significativa sobre distintas métricas tanto técnicas como de negocio. Y, desgraciadamente, por muy bien que preparemos una migración, pueden suceder cosas que hagan que el resultado no sea el óptimo. Bien sea por no haber identificado bien todos los escenarios, por errores durante la implementación o testeo de dicha implementación, porque por decisiones internas no se puedan implementar ciertos requerimientos SEO en una primera iteración y haya que esperar a una siguiente iteración, etc... Y esto nos puede pasar a todos.
En este caso, parece que a corto plazo la migración ha impactado negativamente al índice de visibilidad por un mapeo de redirecciones no óptimo y por no tener etiquetas title únicas y específicas para cada página. JavaScript suele ser el gran señalado siempre que hay una caída en SEO pero, en este caso, parece que solo es culpable de afectar a las Core Web Vitals (y, por ende, la UX).
Será muy intesante ver cómo evoluciona esta migración, puesto que estamos hablando de un sitio web que tiene una autoridad más que notoria para entidades relacionadas con el Real Madrid. Aún sin redirecciones óptimas y sin meta tags óptimos, ¿subirá el índice de visibilidad a corto o medio plazo?
No quiero cerrar el artículo sin darle las gracias a Carlos por abrir este melón. Ha sido muy divertido revisar este proyecto. Kudos for Carlos!
Eres Technical SEO freak? #
Si, como a mí, te apasionan este tipo de análisis casi forenses en los que analizas los pormenores que pueden impactar al rastreo, renderizado e indexación de contenidos trabajando en proyectos bien trufados con JavaScript (y además vives en el área de Barcelona)... WE WANT YOU!
En Schneider Electric tenemos actualmente una posición de Customer Experience Technical SEO Specialist abierta para trabajar conmigo en Barcelona. ¿Te puede interesar? ¡Hablemos! Puedes contactarme a través de Twitter, LinkedIn o Mastodon.